- 掛牌上市企業
- 60秒人工響應
- 99.99%連通率
- 7*24h人工
- 故障100倍補償
<ul id="mayc0"></ul> <ul id="mayc0"></ul> 百度優化:語音識別中聲學模型得分計算優化方法 |
| 發布時間: 2012/9/5 11:10:27 |
|
語音是人們溝通交流最直接、最自然的交互方式。自計算機問世以來,人們就一直希望可以通過語音實現人和計算機之間的交互,而語音識別技術,目標就是通過把人類的語音中的詞匯內容轉換為相應的文本,架起了人機交互的橋梁。對于一個語音識別系統,速度和精度是兩個核心指標,直接決定著系統是否可用。其中,識別速度的提升意味著可以降低成本,同時提供更多的語音服務,一直是語音識別技術研究的重點方向。在語音識別系統中,聲學模型得分的運算量一般會達到整個系統的40%-70%,因此也是識別速度優化的重點模塊。本文就來講講如何優化聲學模型得分計算。
基本概念介紹 特征向量:語音數據在識別前首先會被分成多幀數據,一般幀長為25毫秒,幀移為10毫秒。每一幀語音數據經過特征提取之后,會生成一幀特征,稱之為一個特征向量或特征矢量 HMM state:語音識別中的建模單元,簡稱為state,使用混合高斯模型(GMM)模型描述,每個mixture服從正態分布 似然值:特征向量O在state上的聲學模型得分。其計算步驟分為兩步: a)計算O在每個mixture分量上的似然值,其計算公式為: 其中,j表示state的第j個mixture分量, 其中,m為state中mixture分量的個數, 優化方法 下面先介紹三種無損識別精度的優化方法: 1、代碼加速:使用SSE指令或者intel IPP加速庫 這種方法利用編程語言指令集的優化,通過減少CPU需要操作的指令數來達到加速。其中的intel IPP加速庫直接提供了一套計算似然值的函數庫,加速效果非常明顯,可以達到40%。 2、硬件加速:使用GPU加速 GPU一直以其強大的計算能力著稱,十分適合矩陣相乘這類計算密集型的運算。為了能充分發揮GPU的加速效果,我們需要對似然值的計算公式略作改寫: 經過轉換之后,每個mixture都可以用一個行向量表示,m個mixture可以組成一個大矩陣M = (A1,A2,…,Am)T,同理n幀的特征矢量也可以組成一個矩陣F = (Z1,Z2,…,Zn)。這樣同時求解多個mixture在多幀上的似然值就可以用兩個矩陣的乘積來實現。而每個state各mixture分量的logAdd過程相互獨立,因此這一步也可以在GPU上并行計算。一般情況下,GPU可以達到100倍以上的加速效果,也就意味著GPU可以將原來在語音識別中最耗時的聲學得分計算所占比重降到低于1%。由于這種方法需要一個額外的硬件設備GPU,價格比較昂貴,因而并沒有被大規模使用。 3、 CPU cache加速:一次計算state在多幀特征上的似然值 這種方法利用了語音識別的特點,在識別過程中一旦某個state被激活之后,在后面的連續幾幀中這個state極有可能仍會處于活躍狀態,即在處理后面的特征時還需要計算這個state的似然值。那么我們可以在第一次激活state時,同時計算這個state在從當前幀開始的連續多幀,也不會導致過多不必要的計算。另一方面卻可以利用CPU cache,不用多次從內存中加載state的模型參數到CPU中,從而達到加速的目的。這種方法約有10%的加速效果,一般配合方法1使用。 上面介紹的三種方法,都是對聲學模型得分進行了精確計算,因此不會帶來任何識別精度的下降。如果想做進一步優化,就需要對state的似然值計算公式做些調整。 1、動態高斯選擇法 其思想是用似然值最大的mixture分量來近似logAdd: 那么如何來選出這個最大值呢?大家可能認為這還不簡單?把每個mixture的似然值先計算出來,然后選個最大值就可以了。那接下來我們看看有沒有更好的方法?仔細分析mixture似然值的計算公式: 我們會發現,這是一個隨i增加而遞減的函數。我們可以先計算出 2、高斯選擇法 動態高斯選擇法可以認為是在state的mixture分量里挑出一個最好的,而高斯選擇法認為在state的各個mixture中,只有一到兩個占主導地位(dominant)的mixture,貢獻了整個state的似然值。 動態高斯選擇法是把所有的mixture都計算完了之后才知道哪個最好,和動態高斯選擇法不同,高斯選擇法是直接挑選dominant的mixture,并只計算這些mixture的似然值。其過程大致可以分為3個部分 a)將聲學空間,即聲學模型中所有state的所有mixture劃分成若干個區域,每個區域稱之為一個碼本(codeword) b)生成每個碼本的shortlist,即如何把每個state中的mixture分配到各個碼本中去。 c)在識別過程中,先將特征向量O映射到一個碼本中去,state中落在碼本shortlist的mixture就是dominant的mixture,對這些mixture進行計算。 使用高斯選擇法后,聲學模型打分計算可以降到原來的20%左右,加速效果非常明顯。但是高斯選擇法對如何構建碼本,以及碼本的shortlist有很高要求。不同的構建方法效果會千差萬別,一個好的高斯選擇法帶來的識別率損失非常小,可以做到0.2個點以內。 小結 本文介紹了五種從不同的角度優化聲學模型打分的方法,各自優缺點如下: 1、代碼加速法:簡單實用有效,在實際語音識別系統中可謂是標配。 2、硬件加速法:快!而且快的離譜!能將聲學模型得分計算的負載降到接近0,缺點是成本高,一般只有對識別速度要求非常苛刻時才會使用。 3、CPU cache法:利用了語音識別自身的特點,雖然和其他方法相比,加速效果顯得一般,但優點是可以和其他方法結合使用。在實際使用中還需要謹慎選擇每次連續計算的幀數,避免多余計算。 4、動態高斯選擇法:加速效果中等,對識別率影響較大,一般使用的比較少。 5、高斯選擇法:加速效果僅次于GPU,同時對識別率影響小,可以與代碼加速法結合使用。缺點是這個方法技術難度較高,需要訓練,依賴數據。如果不想花錢,又想達到GPU的效果,這個方法是不錯的選擇。 本文出自:億恩科技【www.vbseamall.com】 |

 京公網安備41019702002023號
京公網安備41019702002023號













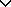

 為協方差矩陣,是對角陣。
為協方差矩陣,是對角陣。





