大數據需要學習什么?很多人問過我這個問題。每一次回答完都覺得自己講得太片面了,總是沒有一個合適的契機去好好總結這些內容,直到開始寫這篇東西。大數據是近五年興起的行業,發展迅速,很多技術經過這些年的迭代也變得比較成熟了,同時新的東西也不斷涌現,想要保持自己競爭力的唯一辦法就是不斷學習。

思維導圖
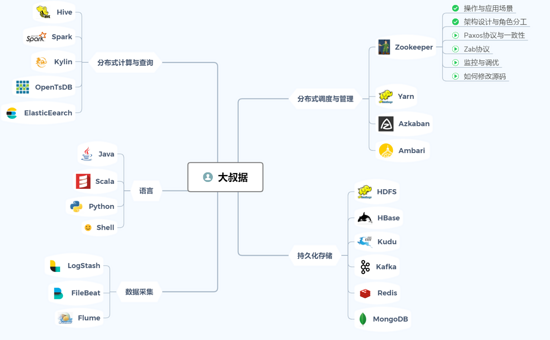
下面的是我整理的一張思維導圖,內容分成幾大塊,包括了分布式計算與查詢,分布式調度與管理,持久化存儲,大數據常用的編程語言等等內容,每個大類下有很多的開源工具,這些就是作為大數據程序猿又愛又恨折騰得死去活來的東西了。
大數據需要的語言 Java
java可以說是大數據最基礎的編程語言,據我這些年的經驗,我接觸的很大一部分的大數據開發都是從Jave Web開發轉崗過來的(當然也不是絕對我甚至見過產品轉崗大數據開發的,逆了個天)。
一是因為大數據的本質無非就是海量數據的計算,查詢與存儲,后臺開發很容易接觸到大數據量存取的應用場景 二就是java語言本事了,天然的優勢,因為大數據的組件很多都是用java開發的像HDFS,Yarn,Hbase,MR,Zookeeper等等,想要深入學習,填上生產環境中踩到的各種坑,必須得先學會java然后去啃源碼。
說到啃源碼順便說一句,開始的時候肯定是會很難,需要對組件本身和開發語言都有比較深入的理解,熟能生巧慢慢來,等你過了這個階段,習慣了看源碼解決問題的時候你會發現源碼真香。
Scala
scala和java很相似都是在jvm運行的語言,在開發過程中是可以無縫互相調用的。Scala在大數據領域的影響力大部分都是來自社區中的明星Spark和kafka,這兩個東西大家應該都知道(后面我會有文章多維度介紹它們),它們的強勢發展直接帶動了Scala在這個領域的流行。
Python和Shell
shell應該不用過多的介紹非常的常用,屬于程序猿必備的通用技能。python更多的是用在數據挖掘領域以及寫一些復雜的且shell難以實現的日常腳本。
分布式計算
什么是分布式計算?分布式計算研究的是如何把一個需要非常巨大的計算能力才能解決的問題分成許多小的部分,然后把這些部分分配給許多服務器進行處理,最后把這些計算結果綜合起來得到最終的結果。
舉個栗子,就像是組長把一個大項目拆分,讓組員每個人開發一部分,最后將所有人代碼merge,大項目完成。聽起來好像很簡單,但是真正參與過大項目開發的人一定知道中間涉及的內容可不少。
比如這個大項目如何拆分?任務如何分配?每個人手頭已有工作怎么辦?每個人能力不一樣怎么辦?每個人開發進度不一樣怎么辦?開發過程中組員生病要請長假他手頭的工作怎么辦?指揮督促大家干活的組長請假了怎么辦?最后代碼合并過程出現問題怎么辦?項目延期怎么辦?項目最后黃了怎么辦?
仔細想想上面的奪命十連問,其實每一條都是對應了分布式計算可能會出現的問題,具體怎么對應大家思考吧我就不多說了,其實已經是非常明顯了。也許有人覺得這些問題其實在多人開發的時候都不重要不需要特別去考慮怎么辦,但是在分布式計算系統中不一樣,每一個都是非常嚴重并且非常基礎的問題,需要有很好的解決方案。
最后提一下,分布式計算目前流行的工具有:
離線工具Spark,MapReduce等 實時工具Spark Streaming,Storm,Flink等
這幾個東西的區別和各自的應用場景我們之后再聊。
分布式存儲
傳統的網絡存儲系統采用的是集中的存儲服務器存放所有數據,單臺存儲服務器的io能力是有限的,這成為了系統性能的瓶頸,同時服務器的可靠性和安全性也不能滿足需求,尤其是大規模的存儲應用。
分布式存儲系統,是將數據分散存儲在多臺獨立的設備上。采用的是可擴展的系統結構,利用多臺存儲服務器分擔存儲負荷,利用位置服務器定位存儲信息,它不但提高了系統的可靠性、可用性和存取效率,還易于擴展。
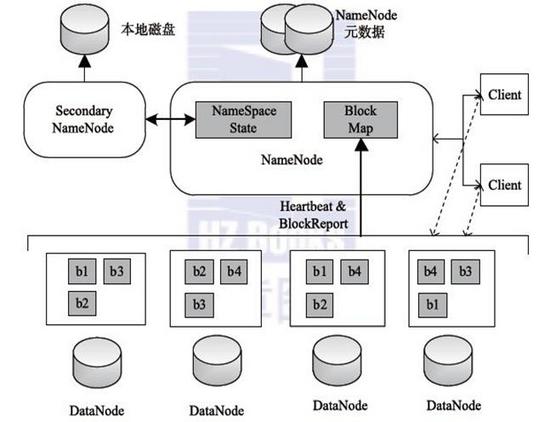
上圖是hdfs的存儲架構圖,hdfs作為分布式文件系統,兼備了可靠性和擴展性,數據存儲3份在不同機器上(兩份存在同一機架,一份存在其他機架)保證數據不丟失。由NameNode統一管理元數據,可以任意擴展集群。
主流的分布式數據庫有很多hbase,mongoDB,GreenPlum,redis等等等等,沒有孰好孰壞之分,只有合不合適,每個數據庫的應用場景都不同,其實直接比較是沒有意義的,后續我也會有文章一個個講解它們的應用場景原理架構等。
分布式調度與管理
現在人們好像都很熱衷于談"去中心化",也許是區塊鏈帶起的這個潮流。但是"中心化"在大數據領域還是很重要的,至少目前來說是的。
分布式的集群管理需要有個組件去分配調度資源給各個節點,這個東西叫yarn; 需要有個組件來解決在分布式環境下"鎖"的問題,這個東西叫zookeeper; 需要有個組件來記錄任務的依賴關系并定時調度任務,這個東西叫azkaban。
當然這些“東西”并不是唯一的,其實都是有很多替代品的,我這里只舉了幾個比較常用的例子。
說兩句
回答完這個問題,準備說點其他的。最近想了很久,準備開始寫一系列的文章,記錄這些年來的所得所想,感覺內容比較多不知從哪里開始,就畫了文章開頭的思維導圖確定了大的方向,大家都知道大數據的主流技術變化迭代很快,不斷會有新的東西加入,所以這張圖里內容也會根據情況不斷添加。細節的東西我會邊寫邊定,大家也可以給我一些建議,我會根據寫的內容實時更新這張圖以及下面的目錄。
關于分組
上面的大數據組件分組其實是比較糾結的,特別是作為一個有強迫癥的程序猿,有些組件好像放在其他組也可以,而且我又不想要分太多的組看起來會很亂,所以上面這張圖的分組方式會稍主觀一些。分組方式肯定不是絕對的。
舉個例子,像kafka這種消息隊列一般不會和其它的數據庫或者像HDFS這種文件系統放在一起,但是它們同樣都具備有分布式持久化存儲的功能,所以就把它們放在一塊兒了;還有openTsDB這種時序數據庫,說是數據庫實際上只是基于HBase上的一個應用,我覺得這個東西更側重于查詢和以及用何種方式存儲,而不在于存儲本身,所以就主觀地放在了“分布式計算與查詢”這一類,還有OLAP的工具也同樣放在了這一組。
目的
大家都知道大數據的技術日新月異,作為一個程序猿想要保持競爭力就必須得不斷地學習。寫這些文章的目的比較簡單, 一是可以當做一個筆記,梳理知識點;二是希望能幫到一些人了解學習大數據 。每一篇的篇幅不會太長,閱讀時間控制在5到10分鐘。我的公眾號大叔據,會同步更新。喜歡看公眾號文章的同學可以關注下,文章的篇幅不會太長,不會占用你太多的閱讀時間,每天花一點時間學習,長期積累總是會有收獲的。
河南億恩科技股份有限公司(www.vbseamall.com)始創于2000年,專注服務器托管租用,是國家工信部認定的綜合電信服務運營商。億恩為近五十萬的用戶提供服務器托管、服務器租用、機柜租用、云服務器、網站建設、網站托管等網絡基礎服務,另有網總管、名片俠網絡推廣服務,使得客戶不斷的獲得更大的收益。
服務器/云主機 24小時售后服務電話:
0371-60135900
虛擬主機/智能建站 24小時售后服務電話:
0371-55621053
網絡版權侵權舉報電話:
0371-60135995
服務熱線:
0371-60135900

